HardiMind RAG
从”文件躺在 Obsidian 里”到”手机飞书一键检索”——我为什么自己做了一个 RAG 系统
1. 问题:知识越多,找到越难
我有很多本地文件——日记、调研笔记、学习文档。几百上千个文件,里面藏着我需要的信息,但想”挖”出来的时候,靠人工翻找几乎不可能。
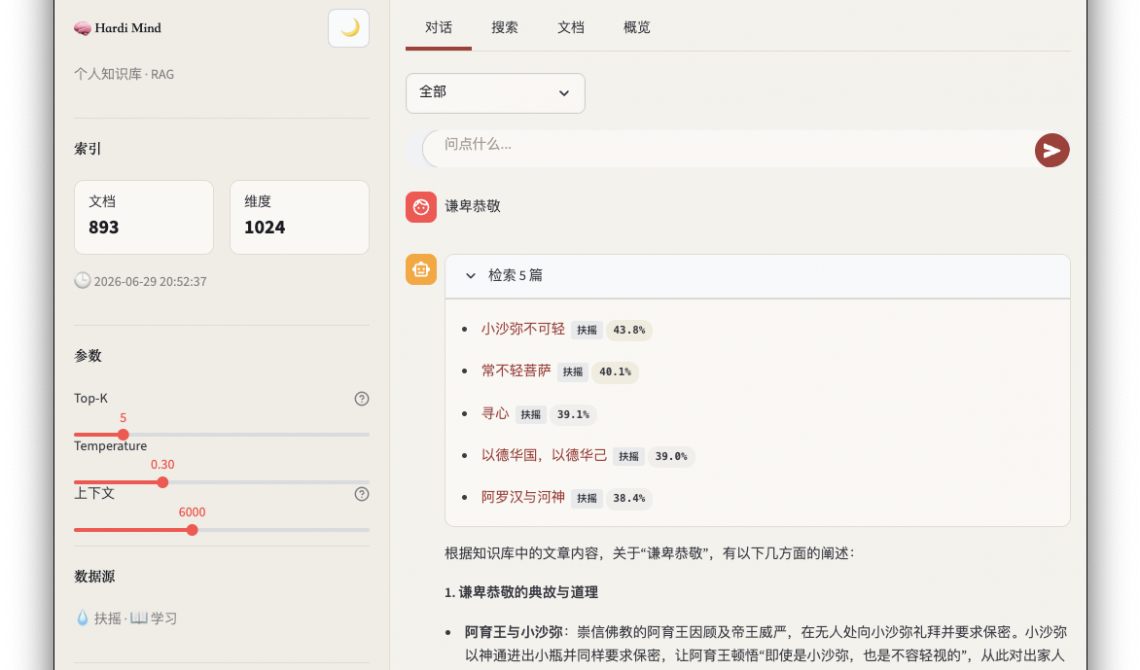
我需要一个系统,能把这些文件向量化索引,然后用自然语言去搜索、提问,直接给我答案。
2. 尝试过的方案,各有各的痛点
先试了 Google NotebookLM,起初效果很惊艳,但想要应用到我自己的生活中时,发现了很多不方便:要手动上传文件。几百个文件一个个传?没有 AI 辅助,管理起来非常复杂,人工成本太高。
再试了 AnythingLLM:本地部署,概念挺好的。但装上之后发现两个致命问题——
第一,太卡。大批量文件处理时电脑明显变慢,而且装一个本地AI LLM后每次回答电脑都卡死,性能扛不住。
第二,需要手动导入。每添加一个新文件,都要进软件手动导入一次,重新做向量化索引。而我的所有知识库文档本来就存在 Obsidian 里,为了用 AnythingLLM,我还得再创建一个副本专门导入进去。每次新增内容都要重复这个流程,非常繁琐。
更关键的是,AnythingLLM 和 OpenClaw(我日常用的 AI Agent 平台)兼容性很差,OpenClaw 经常读不到它里面的数据和信息,API 不好用。这条路走不通。
3. 转机:为什么要自己造轮子
我意识到真正的需求其实很简单:
- 我的文件已经在 Obsidian 里了——为什么还要复制一份?
- 我要的只是一个轻量的、自动化的索引层,能直接读 Obsidian 的原生目录
- 它需要跟 OpenClaw 联动,让我在飞书上直接搜索
- 也要有个 Web 界面,电脑上也能用
这就是 HardiMind RAG 的起点。
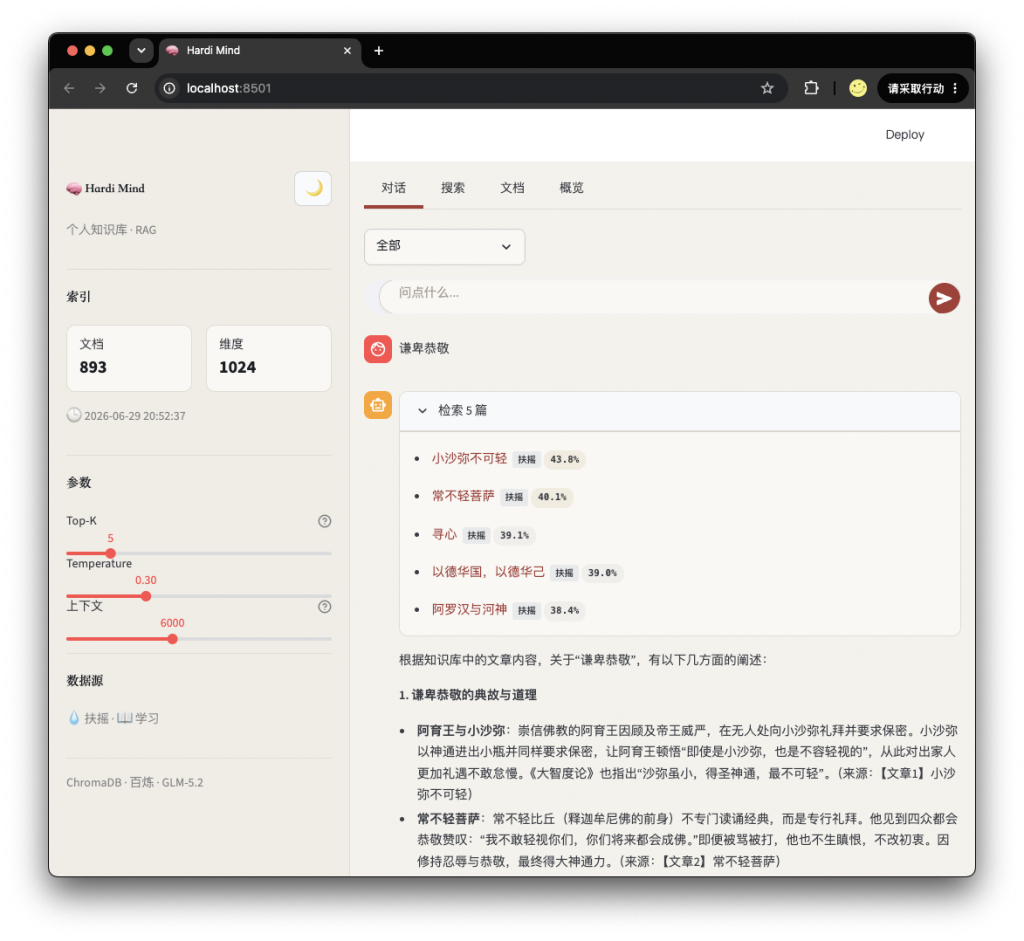
4. 做出来的效果
| 维度 | 之前的方案 | ✅ HardiMind RAG |
|---|---|---|
| 性能 | AnythingLLM 卡到没法用 | 轻量 ChromaDB,几乎无开销 |
| 同步 | 手动导入,还要建副本 | 原位向量化——直接读 Obsidian 原始目录,文件不动 |
| 自动化 | 每次都得人工操作 | 增量索引,新增/修改文件自动发现、自动处理 |
| 检索入口 | 只能在软件界面搜 | 手机飞书发消息就能查 + Web UI 也能查 |
| 检索能力 | 仅向量搜索 | 向量语义 + BM25 全文双引擎 |
5. 一句话总结
文件留在 Obsidian 里,你只管写。新增内容自动索引,飞书对话直接检索,Web 界面也能查。写完即入库,入库即可查。
👉 GitHub 项目::https://github.com/hardihuang/hardimindRAG
Nas Rsync Transfer
家里有一台群晖(Synology)NAS,电脑上有几十个 G 甚至上百个 G 的大量文件需要传输到 NAS 上做备份。
直接走 Wi-Fi 传输,速度慢得让人崩溃——小文件多的时候速度跌到几 MB/s,几十 G 的数据要等几个小时甚至隔夜。而且传输中断了还得从头再来,走硬盘又不一定有这么大容量空闲的硬盘,而且需要先拷贝到硬盘,再插入nas拷贝,过程中很繁琐,而且usb3.0拷贝也没那么快。
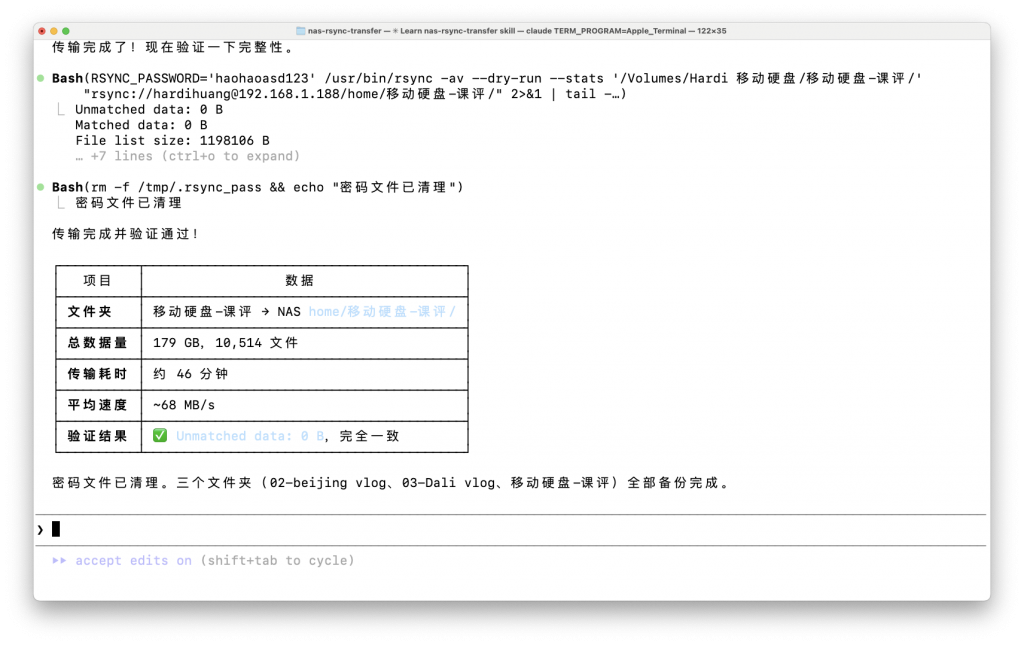
因此用AI研究了下,写了一个skills,传到了github,用rsync的方案给笔记本插网线,效率高,而且可靠,并且可以用claude code监控去传输,断点续传等等,非常适合大批量文件备份的需求。
👉 GitHub 项目:https://github.com/hardihuang/nasRsyncTransfer